Category: Lync
User not in service error
I encountered this issue recently when attempting to Lync call an internal user (P2P, not via PSTN), and was initially a little surprised to see this error message return almost instantly.
![]()
Fair enough if I’d dialed a number that wasn’t valid, but I wasn’t dialing a phone number, and this was a user that I could see was online and available. What the….
In reality the cause is fairly obvious, but to an end-user this could be fairly confusing, so I thought I’d go through the debug process to be thorough. A quick pick through my local trace logs returned this:
history-info: <sip:[email protected]?Reason=SIP%3Bcause%3D302%3Btext%3D%22Moved%20Temporarily%22>;index=1;ms-retarget-reason=forwarding
ms-diagnostics: 13006;reason=”Request forwarded, any previous branches cancelled.”;source=”front-end-servername”;appName=”InboundRouting”
which ultimately resulted in:
SIP/2.0 404 No matching rule has been found in the dial plan for the called number
All this talk of numbers when you’re not dialing a number seems a little odd, until you consider the user-controlled call forwarding feature. Then it all makes sense again.
If a user has elected to forward their calls (not sim-ring) to another number, but have entered a number that cannot be normalised for some reason (could be their fault or yours), then Lync will quite legitimately return the out of service error. Question then becomes, who needs to fix it? The user, or the Lync Admin? How do you know?
To find out, you can consult either the server logs or the SSRS QoE reports. I tend to jump into the QoE reports first in situations like this as it is often quicker. On the QoE report server, run the User Activity Report, bring up calls from the offending user, and open the detail of the call that failed. You will find a number of 404 response codes, and if you drill into the one with a diagnostic ID of 14010, you’ll see the following:
To user URI: sip:00001234567;phone-context=dialplanname@sipdomain.com
Diagnostic header: 14010; reason=”Unable to find an exact match in the rules set”; source=”lyncfe”; CalledNumber=”00001234567“; ProfileName=”dialplanname“; appName=”TranslationService
So in this case, the user is attempting to foward to 00001234567, and Lync is trying to normalise this based on the rules associated with the dial plan listed under ProfileName. It can’t find a rule to match this number format, so fails and essentially rejects the number. From this error detail you can then evaluate the number and determine if the user has fat-fingered an impossible number, or whether perhaps you need to tweak your normalisation rules so this one matches.
Snooper install returns vcredist error
Chances are if you’re trying to install the Lync 2013 Debugging Tools, you may find you receive the following error message:
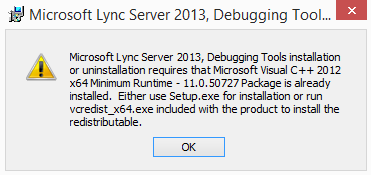
The obvious requirement here is to ensure you have the Visual C++ 2012 x64 Redistributable package installed, and that it be version 11.0.50.727.
The trouble comes when you try and download that version. It’s next to impossible to find as the only versions listed on the official Microsoft sites are either a higher increment of version 11, which doesn’t work, or version 12.x, which also doesn’t work. Frustrating much?
The simple solution is to go dig up your Lync Server 2013 install media, and you’ll find this version in the ~Setupamd64 folder. Install that, and you’re gold.
Alternatively you can download a copy from here, however please be aware this is not an official Microsoft source – its just the copy from my Lync media that I’ve uploaded. It was free of viruses when I uploaded it, in original form, but the internet is a scary place – so make sure you take the necessary precautions if you choose to download it.
Publishing Lync via Web App Proxy with multiple SIP domains
With the recent release of Server 2012 R2, and with it ADFS 3.0 and the Web Application Proxy (WAP) role, word on the street was we now had a replacement product from Microsoft to publish Lync, rather than using the now retired TMG or ISA products.
It’s an exciting time.
So naturally, the minute we upgraded our ADFS farm to 3.0 (as its a hard requirement for deploying WAP), I was straight into test publishing our Lync 2013 platform behind WAP.
Doug Deitterick over on the Microsoft UC Blog has done a great job of documenting how to setup and publish Lync via WAP, and Marc Terblanche has a great post that goes into a bit more detail around scripting the rules, along with some excellent information about the SNI challenge and how to assign a default cert for clients that don’t support SNI (very important to understand this one).
But in both cases, they’re publishing a straight-forward Lync lab, with a single SIP domain. What happens in a real world scenario where you have multiple SIP domains associated with your Lync platform, and you need to publish them all – specifically, if you support mobility?
Unfortunately, the answer is slightly disappointing. You can’t do this via WAP. Yet.
When you have multiple SIP domains, there is a gotcha when it comes to publishing the Lync Discover URL that mobile clients rely on to auto-discover their sign-in server details. In a single SIP domain environment, you’d just have a URL and publishing rule for lyncdiscover.sipdomain.com:443 that points to lyncweb.sipdomain.com:4443. In a multiple SIP domain environment however, you can’t as the mobile clients for users on SIP domain #2 will fail to correctly redirect to the primary SIP domain. The reason for this is outlined below:
Mobile device clients do not support multiple Secure Sockets Layer (SSL) certificates from different domains. Therefore, CNAME redirection to different domains is not supported over HTTPS. For example, a DNS CNAME record for lyncdiscover.sipdomain2.com that redirects to an address of lyncdiscover.sipdomain1.com is not supported over HTTPS. In such a topology, a mobile device client needs to use HTTP for the first request, so that the CNAME redirection is resolved over HTTP. Subsequent requests then use HTTPS. To support this scenario, you need to configure your reverse proxy with a web publishing rule for port 80 (HTTP). For details, see “To create a web publishing rule for port 80” in Configuring the Reverse Proxy for Mobility.
(quoted from ‘Technical Requirements for Mobility’ at http://technet.microsoft.com/en-us/library/hh690030.aspx)
Under TMG, this isn’t a problem, as you can simply create an additional publishing rule for each additional SIP domain on HTTP, which redirects clients to the Lync webservices on 8080. This allows the initial request to come in on HTTP, perform the redirection to the webservices endpoint, then perform subsequent requests directly, via HTTPS.
Why doesn’t this work with WAP? Because as at RTM, the WAP feature only allows you to publish HTTPS URLs. If you attempt to publish anything via HTTP, WAP will return and error and come to a hard stop.
From what I’ve heard, this is something Microsoft are working hard to bring to the product as they recognise it is a barrier to entry for Lync publishing, though whether that will be via an update or a future version I’m unsure at this time.
In the meantime, it looks like your TMG platform might need to stick around a fraction longer if you have multiple SIP domains in your environment. Fingers crossed you wont have to wait too long though.
JB
Lync 2013 Monitoring and Mirroring Gotcha
If you don’t configure your 2013 platform for SQL mirroring from the outset (or at least, prior to deploying the Lync Reports), then add mirroring later, you’ll find your Lync Monitoring Reports stop working when you failover the SQL servers.
Reason being is the report deployment will configure its datasources for the SQL instance(s) its aware of at deployment time, and subsequent changes to SQL topology wont be updated in the datasources later.
Not a major to fix, you’ll just need to change your datasource connection strings.
1. Open your SSRS front end http://<server>/reports
2. Open the Reports_Content Folder
3. Edit the properties of both CDRDB and QMSDB datasources
4. Change the connection strings to use the following syntax:
Data Source=SQLServer1SQLInstance;Failover Partner=SQLServer2SQLInstance;initial catalog=<DBName>
5. Re-enter your report user password and hit Test Connection to ensure it works, then Apply and you’re done.
Wellington IUG | Lync 2013 Migration Pro-Tips | April 9th @ 5pm
I’ll be presenting a usergroup session on Lync 2013 in early April down in Wellington at Microsoft’s recently refurbished office (Level 12, 157 Lambton Quay) – you should come – it’ll be great.
Lync 2013 is here – planned your upgrade yet?
Lync 2013 is here, and it’s action-packed full of fantastic new features that will quite honestly change your life. If, like many organisations, you drank the kool-aid a while back and deployed OCS or Lync 2010, you’ll be asking yourself whether you should be upgrading, and how you go about it.
We’ll do a whistle-stop tour through the pick of the new features – hopefully helping you build your business case to upgrade – and run step-by-step through a Lync 2010-2013 upgrade, including a few lessons from the field to save you some pain.
Registration is required for this event – please do so here if you’d like to attend. (did I mention there’s free beer and pizza?)
Lync Hold Issue
In a recent Enterprise Voice deployment I struck an issue where a small number of users couldn’t place a call on hold. When they tried, the Lync client errored with “Failed to place call on hold” and instead put the client’s mic and speakers on mute. Removing this mute sometimes worked and sometimes resulted in a dropped call.
All users in this particular deployment were subject to the same client policy, same client version, same voice routing.. generally, everything was the same from one user to the next.
After running some S4/SIPStack trace logs on the gateway, and analysing the SIP Options packet that was being sent to the SIP gateway, I could see that in a working request, the SIP Invite that got sent included a=inactive (which is normal), whereas in a failing request, the Invite sent a=sendonly instead. What I couldn’t figure out was why two clients with the same settings/policy/routes would send two different hold methods. What made this particularly odd was that the user that was having the issue could log on to a different computer, and placing a call on hold would work fine.
So, issue had to be client-side.
One of the things I looked at during the debug process was the Lync registry entries. After painstakingly comparing registry keys line by line, I found that only one of the clients had the MusicOnHold registry keys listed – and it was the one that wasn’t working. Looking at the client options (Tools > Options > Alerts) showed that both had the same options selected (in this case, ‘Enable Music on Hold’ was ticked and greyed out (managed by policy), and the hold music file was populated with the default wma file), yet on the client that was working fine, the two MusicOnHold registry keys (below) were completely missing.
[HKEY_CURRENT_USERSoftwareMicrosoftCommunicator]
“MusicOnHoldDisabled”=dword:00000000
“MusicOnHoldAudioFile” =”C:Program Files (x86)Microsoft LyncMediaDefaultHold.wma”
After backing up the keys, I deleted the MusicOnHoldAudioFile key, and rebooted. Bingo. Problem solved.
Tried reinstating the key again, and sure enough, problem returned immediately.
I have come across one other customer having the same issue, and they apparently found the problem disappeared when they apply CU5, however I haven’t been able to verify that completely with them, and when I tried the CU5 update, the issue persisted.
Why exactly this happens is soon to be the subject of a support ticket with Microsoft. When I get an outcome from that, I’ll be sure to update this post.
Gotcha – Integrating Lync On-Prem with Exchange Online UM
As part of our (Provoke’s) recent migration of our corporate email to Office 365 and Exchange Online, we wanted to include migration of the Exchange Unified Messaging role to Exchange Online as well. Simple enough, and the UCGuys have a superb post that breaks down the process in real simple terms.
However..
We struck an issue after completing the process whereby calling voicemail, or trying to dial the UM dial-in numbers failed. Checking the logs revealed an error along the following lines:
ms-diagnostics: 1036; reason=”Previous hop shared address space peer did not report diagnostic information”; source=”<fe-server>”; dialplan=”Hosted__exap.um.outlook.com__<multipleSMTPdomains>”; umserver=”exap.um.outlook.com”;responsecode=”503″; msexchDomain=”<primarySMTPdomain>”; msexchPeerServer=”exap.um.outlook.com”; msexchsource=”<edgeaccessfqdn>”; appName=”ExumRouting”
Followed by:
ms-diagnostics: 15030; reason=”Failed to route to Exchange Server”; source=”<fe-server>“;dialplan=”Hosted__exap.um.outlook.com__<multipleSMTPdomains>“; appName=”ExumRouting”
Turns out we (and by that I mean me) had made an error when running the command:
New-CsHostedVoicemailPolicy -Identity Office365UM -Destination exap.um.outlook.com -Description “Hosted voice mail policy for O365 users.” -Organization “domain.com”
In my desire to validate blog posts before blindly following them (crazy right!), I’d checked the UCGuys’ NewCsHostedVoicemailPolicy syntax against the Technet cmdlet library for New-CsHostedVoicemailPolicy, which states for the Organisation field..
This parameter contains a comma-separated list of the Exchange tenants that contain Lync Server 2010 users. Each tenant must be specified as an FQDN of the tenant on the hosted Exchange Service.
Which I duly interpreted as meaning all SMTP domains associated with the Exchange Online tenant – of which we had three. Especially as the example syntax at the bottom of the article does exactly that.
Turns out, that aint gonna fly.
For Exchange Online UM, you must specify one domain only in the Organisation field. And that domain must be one that Exchange Online is authorative for. If you’ve done a cutover migration, that will mean you can probably use your primary SMTP domain, as by dint of the cutover, Exchange Online will be authorative for that domain. However if you’ve done a hybrid migration, chances are good that your on-premise Exchange platform is still authorative for your primary SMTP domain. So best option here is to use your <customer>.onmicrosoft.com domain, as Exchange Online will always be authorative for that one.
This is briefly outlined at the end of the Connect Lync Server 2010 to Exchange Online UM Checklist from Microsoft.
The Lync ‘How To’ Guide
If you’re implementing Lync, or already have it, chances are user training is/was part of the implementation. Great. But what about those “remind me how I..” and “what does this do again?” that you know will come up?
Microsoft have done you a huge favour here.
I personally think Lync is hands-down the most superbly well documented product ever to roll out the doors of Redmond. Sure there’s stuff that could be better documented, but the planning, implementation, support, and (yup) training material available is beyond compare.
There is a huge list of pre-canned resources available at http://lync.microsoft.com/Adoption-and-Training-Kit/rollout-and-adoption/Pages/Resources/Intro-to-Resources.aspx that includes the likes of reference sheets, training decks, and videos, but what I really want to flag for attention is the ‘How To Guide’. Quite simply – it’s brilliant.
The guide is a Silverlight and/or HTML web application that contains a huge range of common (and not so common) Lync user tasks, presented in a sensibly structured manner that any user should have no issue following. It even comes with a handy set of instructions that outlines how to easily add your own items to the list – useful if you perhaps have a custom app integrated with your Lync platform.

The package can be downloaded from http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=5735
Setup is a peice of cake, and should take less than five minutes. Here’s the basics for IIS7/7.5
- Create a folder on your webserver
- Extract contents of the zip file
- Create an IIS site and point it at the folder you created
- Define your default document as either rolodex.html (for Silverlight version) or jQueryRolodex.html (for the HTML version).
- Configure your host headers and DNS entries
- Done
The only difference if you’re doing this on older versions of IIS is you need to manually create a MIME type for .xap extensions, defined as application/x-silverlight-app
Lync On-Premises vs Lync Online
A common question about Lync Online (and the other Office 365 products too, but this post is Lync-centric) is “how is this different from the on-premises solution?” And there is a comprehensive feature comparison available at the Office 365 Community site, but usually the next question I get is “yeah yeah, but what does that really mean for me?”
So here’s a shortlist of the more pertinant features that you don’t get with Lync Online.
- PSTN calling (incoming or outgoing)
- PBX integration
- Advanced call handling (hold, redirection, park)
- IP Phone support (USB only)
- Analog line support (eg. fax)
- Response groups (ie. Direct inbound call to a recipient group)
- Persistent group chat
- Skill search from SharePoint (either on-premise or online)
- Client-side recording
- Dial-in conferencing
- Interop with on-premise video conferencing systems (eg. Polycom suites)
- QoS
- Quality of Experience Reporting
This usually leads to a question like, “ok, so what do they have in common then?”
So for completeness, here’s some of the more popular things you can do with both versions of the product.
- PC-to-PC audio/video
- Address book search
- IMPresence
- Office application integration (click-to-chat)
- Federation with Lync Online, Lync On-Premise, and OCS On-Premise
- Application/Desktop/Whiteboard/Presentation sharing
- Online Meetings
- Guest attendees (via rich client and web client)
- Roundtable support
- Meeting lobby
Hope that’s helpful. Might add SharePoint Online and Exchange Online comparisons too.
On The Socials



How to delete those annoying duplicate Lync contacts
November 25, 2015
Lync, Skype for Business
No Comments
gingerninjanz
The underlying cause of these duplicates being created has long been fixed via CUs, but the contacts remain. The trouble with removing these if you’re on Exchange Online is the contacts have special permissions and can’t be deleted by the end user.
I needed to solve this problem recently, and found plenty of suggested fixes but they were either way too manual (fine for a few duplicates but not thousands) or they just didn’t work at all.
Being a fan of all things PowerShell, I dug out some cmdlets and figured out how to do it via PowerShell, which I’ll spell out below. I’ve included a full copy of the script at the end of this post if you just want to steal the whole thing. Go for it.
To do this you’ll need a PowerShell window (no special modules required) and an account with the global admin role. (To be honest I’ve been lazy here, there will be a combination of role permissions lower than global admin that enables this, I just haven’t figured out what they are yet)
First up, the basics. Get yourself connected to Exchange Online via PowerShell.
Next create a mailbox to store the log output. I’d recommend using a shared mailbox so it doesn’t consume a license. Be sure to grant yourself access to the mailbox so you can review outputs.
Now to find the offending contacts. We use a mailbox search query to iterate over all mailbox items that contains the unique string that each duplicate contains. The output of the search is saved to the shared mailbox you created above to allow you to verify the query returns only those items you want.
I’ve included a few sample queries to get you started.
1. Query against a single mailbox
2. Query multiple mailboxes
3. Query all mailboxes
Note that these commands will include the dumpster by default. If you want to exlude the mailbox dumpster from the query, add “-SearchDumpster:$false” to the end of the command. There is also a return item limit of 10,000 items per mailbox.
# Example 1 - For a single mailbox Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnly # Example 2 - For a couple of mailboxes Get-Mailbox | ?{$_.alias -eq '' -OR $_.alias -eq ';' -or $_.alias -eq ''} | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnly # Example 3 - For all mailboxes Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnlyOpen the shared mailbox via Outlook and locate the TargetFolder path you used. This will include a mail object with the results of the query you ran, and a CSV file attachment containing the precise results down to a per-contact level. Validate your results are as you expect, and then either proceed with deletion, or refine your query and re-run the search.
Once you’re happy with your query and the output you’re getting, time to hit delete. This is basically just a case of using the -DeleteContent flag on the same query command you used above.
If you use the ‘all mailboxes’ query this may take a very long time. In my case I had about 150 mailboxes with 350,000 duplicate contacts. The deletion process took 7 hours to complete.
Due to the query return item limit, this will only delete 10,000 items from each mailbox at a time. Pending on how many duplicates your users have you may need to run this more than once (I did).
# For a single mailbox Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent # For a couple of mailboxes (this filter uses the mailbox alias value, but you could filter on any field that makes sense to you) Get-Mailbox | ?{$_.alias -eq '' -OR $_.alias -eq '' -or $_.alias -eq ''} | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent # For all mailboxes - note this could take a loooong time. Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent -SearchDumpster:$falseThat’s it – job done.
Technically you should remove the shared mailbox you created at the beginning to clean this up. I left mine in place for a while as a lazy log of what was removed, but deleted it once I was happy nobody was upset by the sudden removal of 350,000 completely useless contact objects. That and of course close your session like a good ‘sheller should.
If you’re looking for the entire script, you’ll find it below. Hope it’s useful.
JB
# Get yourself connected to Exchange Online $cred = get-credential $session = New-PSSession -ConfigurationName Microsoft.Exchange -ConnectionUri "https://ps.outlook.com/powershell/" -Credential $cred -Authentication Basic -AllowRedirection Import-PSSession $session -AllowClobber # First create a destination mailbox for query reports. Use a shared mailbox so it doesn't consume a license New-Mailbox -Name LyncContactRemoval -Shared # Grant yourself access to the mailbox so you can open via Outlook Get-Mailbox LyncContactRemoval | Add-MailboxPermission -User <your-mailbox-upn> -AccessRights FullAccess -InheritanceType All # Query for candidates and log results (no other action taken) # Example 1 - For a single mailbox Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnly # Example 2 - For a couple of mailboxes (this filter uses the mailbox alias value, but you could filter on any field that makes sense to you) Get-Mailbox | ?{$_.alias -eq '' -OR $_.alias -eq ';' -or $_.alias -eq ''} | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnly # Example 3 - For all mailboxes Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -TargetMailbox LyncContactRemoval -TargetFolder Cleanup -LogLevel Full -LogOnly # Note - these commands will include the dumpster by default. If you want to exlude the mailbox dumpster from the query, add "-SearchDumpster:$false" to the end of the command # Open the mailbox in Outlook and locate the TargetFolder path you used. This will include a mail object with the results of the query, and a CSV file attached containing the precise results down to a per-contact level. Validate your results are as you expect, and then either proceed with deletion, or refine your query and re-run the search. # To actually delete the objects.. do this # For a single mailbox Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent # For a couple of mailboxes (this filter uses the mailbox alias value, but you could filter on any field that makes sense to you) Get-Mailbox | ?{$_.alias -eq '' -OR $_.alias -eq '' -or $_.alias -eq ''} | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent # For all mailboxes - note this will take a loooong time. For 232 mailboxes with 350,000 duplicate contacts, this process took 7 hours to complete. Get-Mailbox | Search-Mailbox -SearchQuery 'all:"This contact was updated from Microsoft Lync" OR all:"This contact was added from Microsoft Lync"' -DeleteContent -SearchDumpster:$falsePowerShellSfB